基本概念
贪心(Greedy)是最容易理解的算法思想:把整个问题分解成多个步骤,在每个步骤都选取当前步骤的最优方案,直到所有步骤结束;在每一步都不考虑对后续步骤的影响,在后续步骤中也不再回头改变前面的选择。
贪心法看起来似乎并不靠谱,因为局部最优的组合不一定是全局最优的。那么,是否有一些规则使得局部最优能达到全局最优。例如下面的最少硬币问题:
最少硬币问题
最少硬币问题
某人带着3种面值的硬币去购物,有1元、2元、5元的,硬币数量不限;他需要支付M元,请问怎么支付才能使硬币数量最少?
思路: 根据生活常识,第一步应该拿出面值最大的5元硬币,第二步拿出面值第2大的2元硬币,最后才拿出最小的1元硬币。在这个解决方案中,硬币数量总数是最少的。
程序如下:
# include <bits/stdc++.h>
using namespace std;
const int NUM = 3;
const int Value[NUM] = {1, 2, 5};
int main(){
int i, money;
int ans[NUM] = {0};
cin>>money;
for(i = NUM - 1; i >= 0; i--){
ans[i] = money / Value[i];
money = money - ans[i] * Value[i];
}
for(i = NUM - 1; i>=0;i--){
cout << Value[i] << "元硬币数" << ans[i] << endl;
return 0;
}
}
在上面的例子中,虽然每一步选硬币的操作并没有从整体最优考虑,只在当前步骤选取了局部最优,但结果是全家最优。然而,局部最优并不总能导致全局最优。比如这个最少硬币问题,用贪心法一定能得到最优解吗?
分析:在最少硬币问题中,如果稍微改下参数,就不一定能得到最优解,甚至在有解的情况下也无法给出答案。
(1)不能得到最优解的情形。例如,硬币的面值比较奇怪,是1、2、3、4、5、6元,支付9元,如果使用上面的贪心法,答案是6+2+1,需要3个硬币,而最优的5+4只需要两个硬币。
(2)算不出答案的情形。例如,如果有面值1元的硬币,能保证用贪心法得到一个解,如果没有1元硬币,常常得不到解。用面值2、3、5元的硬币,支付9元,用贪心法无法得到解,但解是存在的,即9=5+2+2。
所以,在最少硬币问题中是否能使用贪心法跟硬币的面值有关。一个简单的判断标准是,面值是整数c的幂,其中c>1,可以使用贪心法。例如以2的倍数递增的1、2、4、8等,这样的面值就符合条件。
总结:用贪心法求解的问题需要满足以下特征:
(1)最优子结构性质。当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质,也称此问题满足最优性原理。也就是说,从局部最优能扩展到全局最优。
(2)贪心选择性质。问题的整体最优解可以通过一系列局部最优的选择来得到。
贪心算法没有固定的算法框架,关键是如何选择贪心策略。贪心策略必须具备无后效性,即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
另外,对于某些难解问题,例如旅行商问题,很难得到最优解,但是此时用贪心法常常能得到不错的近似解。如果不一定非要求得最优解,那么贪心的结果也是很不错的方案。
活动安排问题
活动安排问题
有很多电视节目,给出它们的起止时间,有点节目时间冲突,问能完整看完的电视节目最多有多少?
思路:解题的关键在于选择什么贪心策略才能安排尽量多的活动。由于活动有开始时间和结束时间,考虑下面3种贪心策略:
(1)最早开始时间。
(2)最早结束时间。
(3)用时最少。
经过分析发现,第1种策略是错误的,因为如果一个活动迟迟不终止,后面的活动就无法开始。第2种策略是合理的,一个尽快终止的活动可以容纳更多的后续活动。第3种策略也是错误的。
对最早结束时间进行贪心,算法步骤如下:
(1)把n个活动按结束时间排序。
(2)选择第1个结束的活动,并删除(或跳过)与它时间相冲突的活动。
(3)重复步骤(2),直到活动为空。每次选择剩下的活动中最早结束的那个活动,并删除与它时间冲突的活动。
分析:上述贪心算法是否能保证得到全局最优解?
(1)它符合最优子结构性质。选中的第1个活动,它一定在某个最优解中。同理,选中第2个活动、第3个活动等也都在这个最优解中。
(2)它符合贪心选择性质。算法的每一步都使用了相同的贪心策略。
struct node{
int start,end;
} record[MAXN];
bool cmp(const node& a, const node& b){return a.end < b.end;}
for (int i = 0, i < n ; i++)
cin>>record[i].start>>record[i].end;
sort(record, record + n, cmp);
int count = 0;
int lastend = -1;
for(int i=0; i<n; i++){ //贪心算法
if(record[i].strat >= lastend){ //后一个起始时间大于等于前一个终止时间
count++;
lastend = record[i].end; //记录前一个活动的终止时间
}
}
cout<< count <<endl; //输出活动个数区间覆盖问题
区间覆盖问题
给定一个长度为n的区间,再给出m条线段的左端点(起点)和右端点(终点),问最少用多少条线段可以将整个区间完全覆盖?
贪心思路是尽量找出更长的线段。其解题步骤如下:
(1)把每个线段按照左端点递增排序。
(2)设已经覆盖的区间是[L,R],在剩下的线段中找出所有左端点小于等于R且右端点最大的线段,把这个线段加入到已覆盖区间里,并更新已覆盖区间的[L,R]值。
(3)重复步骤(2),直到区间全部覆盖。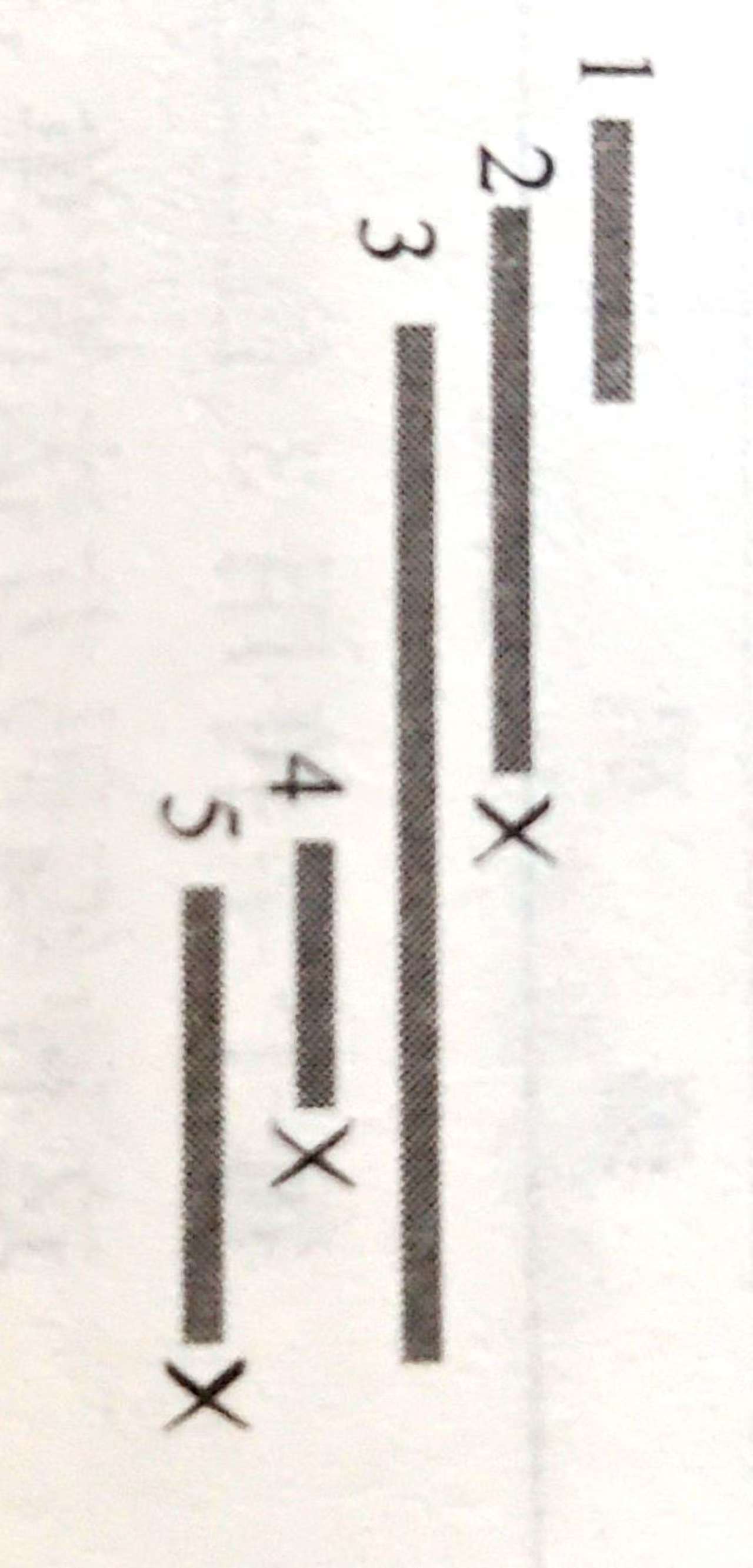
最优装载问题
最优装载问题
有n种药水,体积都是V,浓度不同,把它们混合起来,得到浓度不大于w%的药水,问怎么混合才能得到最大体积的药水?注意,一种药水要么全用,要么都不用,不能只取一部分。
题目要求配置浓度不大于w%的药水,那么贪心的思路就是尽量找浓度小的药水。先对药水按浓度从小到大排序,药水的浓度不大于w%就加入,如果药水的浓度大于w%,计算混合后的总浓度,不大于w%就加入,否则结束判断。
多机调度问题
多机调度问题
设有n个独立的作业,由m台相同的计算机进行加工。作业i的处理时间为 $ t_{i} $ ,每个作业可在任何一台计算机上加工处理,但不能间断、拆分。要求给出一种作业调度方案,在尽可能短的时间内,由m台计算机加工处理完成这n个作业。
求解多机调度问题的贪心策略是最长处理时间的作业优先,即把处理时间最长的作业分配给最先空闲的计算机。让处理时间长的作业得到优先处理,从而在整体上获得尽可能短的处理时间。
(1)如果n<=m,需要的时间就是n个作业当中最长的处理时间t。
(2)如果n>m,首先将n个作业按处理时间从大到小排序,然后按顺序把作业分配给空闲的计算机。
Huffman编码
Huffman编码是贪心思想的典型应用,是一个很有用的、很著名的算法。Huffman编码是“前缀”最优编码。
首先了解什么是编码。
把一段字符串存储在计算机中,这段字符包含很多字符,每种字符出现的次数不一样,有点频次高,有点批次低。因为数据在计算机中都是用二进制码来表示。例如给出一段字符串,它只包含A、B、C、D、E这五种字符,编码方案如下表。
| 字符 | A | B | C | D | E |
|---|---|---|---|---|---|
| 频次 | 3 | 9 | 6 | 15 | 19 |
| 编码 | 000 | 001 | 010 | 011 | 100 |
每个字符用3位二进制数表示,存储总长度是 $ 3 \times \left ( 3+9+6+15+19 \right ) = 156 $ .
这种编码方法简单、实用,但不节省空间。由于每个字符出现的频次不同,可以想到用变长编码;出现次数多的字符用短码表示,出现少的用长码表示。如下表。
| 字符 | A | B | C | D | E |
|---|---|---|---|---|---|
| 频次 | 3 | 9 | 6 | 15 | 19 |
| 编码 | 1100 | 111 | 1101 | 10 | 0 |
存储的总长度是 $ 3 \times 4 + 9 \times 3 + 6 \times 4 + 15 \times 2 + 19 \times 1 = 112 $ .
第2种方法相当于第1种方法进行了压缩,压缩比是 156/112 = 1.39 .
当然,编码算法的基本要求是编码后得到的二进制串能唯一地进行解码还原。上面第1种方法是正确的,每3位二进制数对应一个字符。第2种方法也是正确的,例如“11001111001101”,解码后唯一得到的“ABDEC”。
如果胡乱设定编码方案,很可能是错误的,例如下表。
| 字符 | A | B | C | D | E |
|---|---|---|---|---|---|
| 频次 | 3 | 9 | 6 | 15 | 19 |
| 编码 | 100 | 10 | 11 | 1 | 0 |
看起来似乎每个字符都有不同的编码,编码后的总长度也更短, $ 3 \times 3 + 9 \times 2 + 6 \times 2 + 15 \times 1 + 19 \times 1 = 73 $. 但是编码无法解码还原,例如“100”,是”A”、”BE”还是”DEE”呢?
错误的原因是,某个编码是另一个编码的前缀(prefix),即这两个编码有包含关系,导致了混淆。
那么有没有比第2种编码方法更好的方法?这引出了一个字符串存储的常见问题:给定一个字符串,如果编码,能使编码后的总长度最小?即如何得到一个最优解?
确定Huffman编码的最优解
按照Huffman编码的思想,将出现频次高的字符,用尽可能少的字符进行编码。所以我们就必须先统计各个字符出现的顺序,并进行排序。如下表:
| 字符 | A | C | B | D | E |
|---|---|---|---|---|---|
| 3 | 6 | 9 | 15 | 19 |
根据上表我们应该让E使用最小的字符来编码,但同时也要避免其编码过于简单,成为后面字符的前缀。同时思考这两个条件,很难让人有足够的自信证明自己的解为最优解。这时候,我们就要引入贪心法了。
由于编码是二进制的,且每个字符编码长度不同,这让我们很容易联想到二叉树。贪心的过程就是按出现的频次从底层往顶层生成二叉树。注意,每一步都要按频次重新排序(见下面样例说明)。这个过程可以保证出现频次少的字符被放在树的最底层,编码更长;出现多的字符被放在上层,编码更短。如下图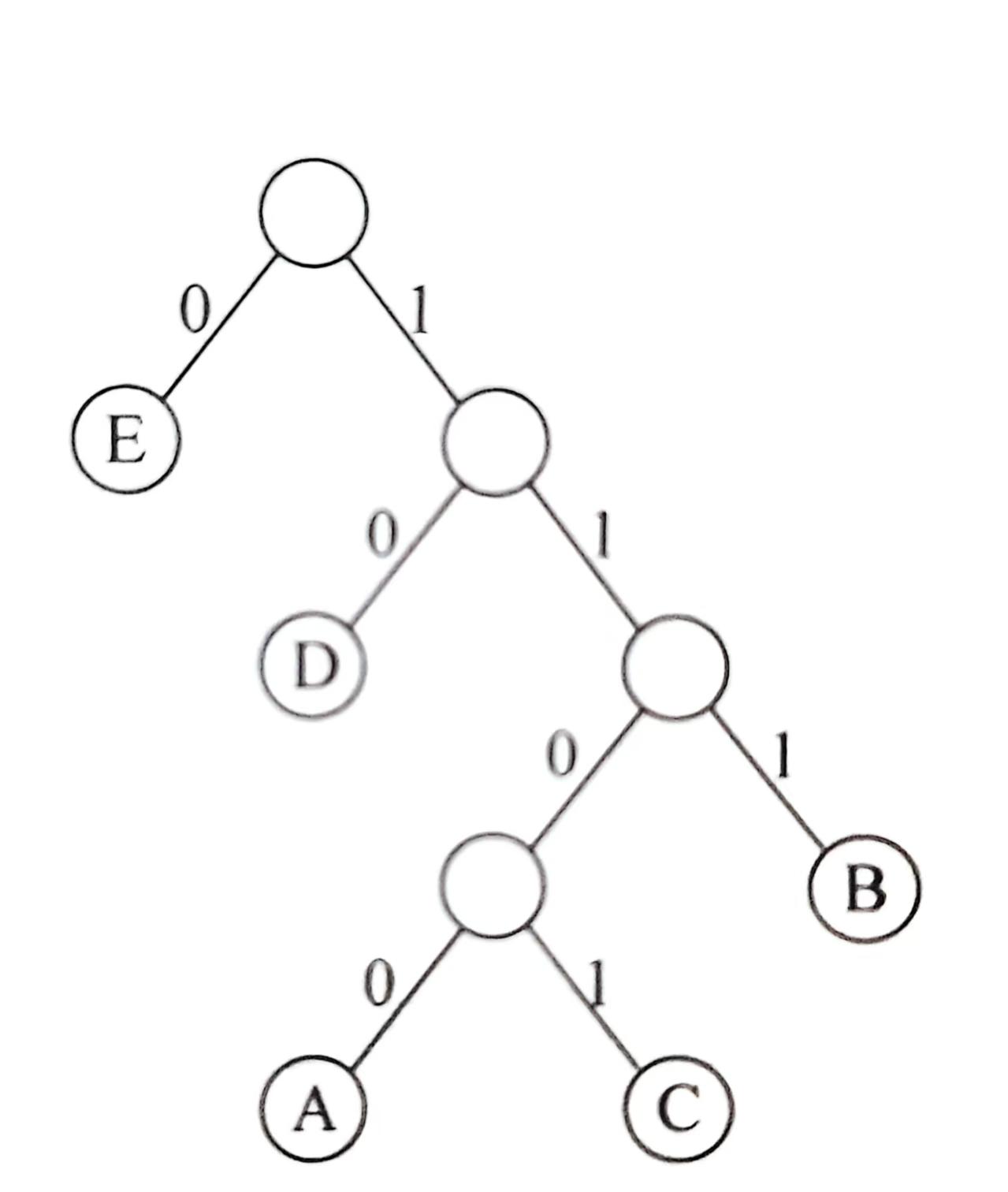
事实上通过二叉树来确定每个字符的编码,已经是最优情况。具体证明见《算法导论》,Thomas H.Cormen等著,潘金贵等译,机械工业出版社,234页,“赫夫曼算法的正确性”。
样例说明
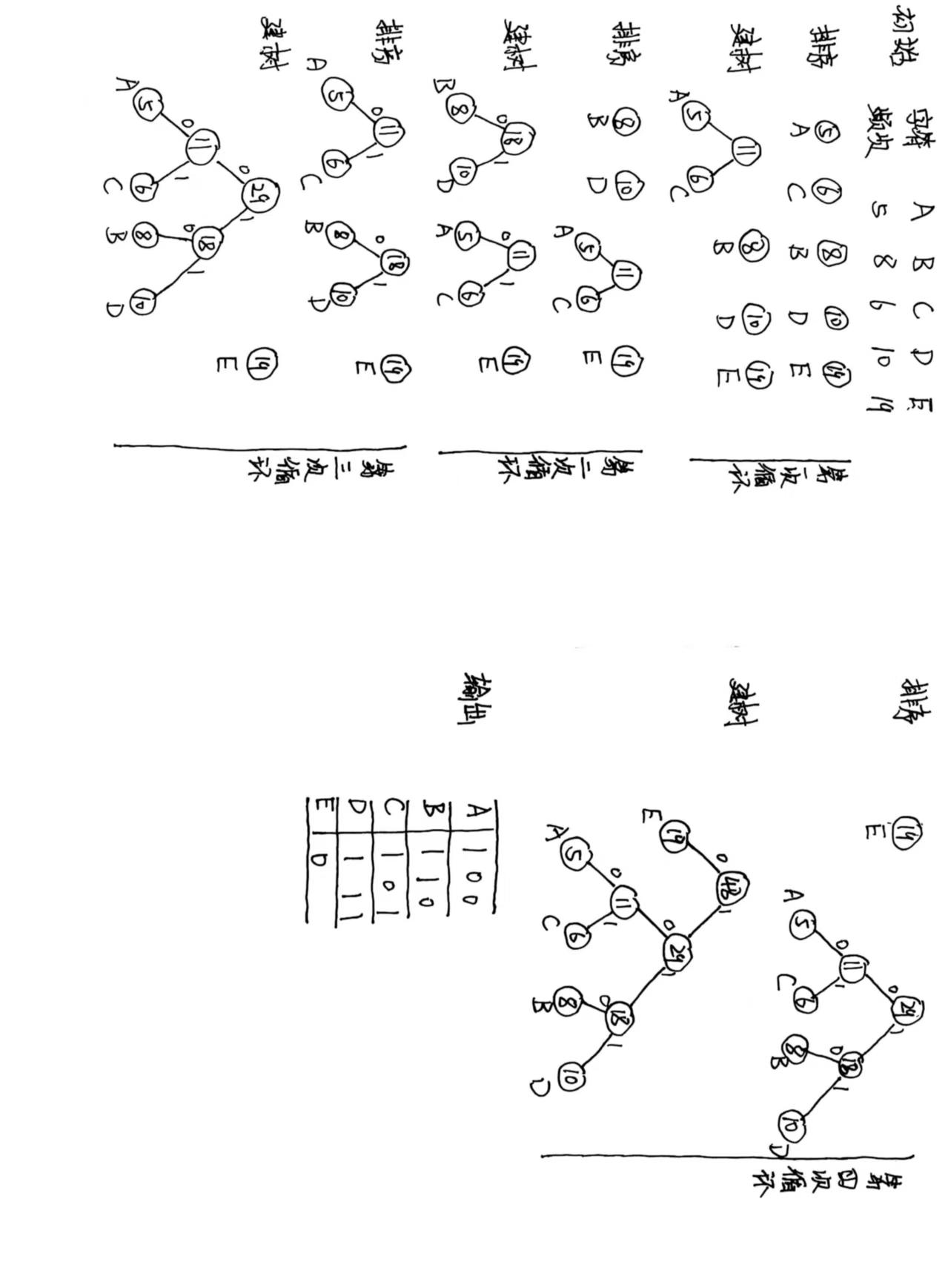
例题
Entropy
输入一个字符串,分别用普通ASCII编码(每个字符8bit)和Huffman编码,输出编码后长度,并输出压缩比。
输入样例:
AAAAABCD
输出样例:
64 13 4.9
这一题正常的解题过程是首先统计字符出现的频次,然后用Huffman算法编码,最后计算编码后的总长度。不过,由于只需要输出编码的总长度,而不要求输出每个字符的编码,所以可以跳过编码过程,利用Huffman编码思想,直接计算编码的长度。
下面代码使用了STL的优先队列,在每个贪心步骤,从优先队列中提取频次最低的两个字符。
string s;
priority_queue<int, vector<int>, greater<int>> Q;
//优先队列,最小的在队首
while(getline(cin,s) && s!= "END"){//输入字符串
int t =1;
sort(s.begin(), s.end());
for(int i = 1;i<s.length();i++){//统计字符出现的频次,并放进优先队列
if(s[i] == s[i-1]) {
Q.push(t);
t =1 ;
}
else t++;
}
Q.push(t);
int ans = 0;
while(Q.size() > 1) {//每次取出两个最小的字符频次,合并成一个新的字符频次
int a = Q.top();
Q.pop();
int b = Q.top();
Q.pop();
Q.push(a + b);
ans += a + b;
}
Q.pop();
}
return 0;
模拟退火
模拟退火算法基于这样一个物理原理:一个高温物体降温到常温,温度越高时降温的概率越大(降温更快),温度越低时降温的概率越小(降温更慢)。模拟退火算法利用这样一种思想进行搜索,即进行多次降温(迭代),直到获得一个可行解。
在迭代过程中,模拟退火算法随机选择下一个状态,有两种可能:①新状态比原状态更优,那么接受这个新状态;②新状态更差,那么以一定的概率接受这个状态,不过这个概率应该随时间的推移逐渐降低。
模拟退火算法是贪心思想和概率的结合,常用“爬山”问题来介绍贪心有关的算法,在下图中,A是局部最高点,B是全局最高点。普通的贪心算法,如果当前状态在A附近,会一直爬山,最后停止在局部最高点A,而无法到达B。模拟退火算法能跳出A,得到B。因为它不仅往上爬山,而且以一定的概率接受比当前点更低的点,使程序有机会摆脱局部最优到达全局最优。这个概率会随时间不断减小,从而最后能限制在最优解附近。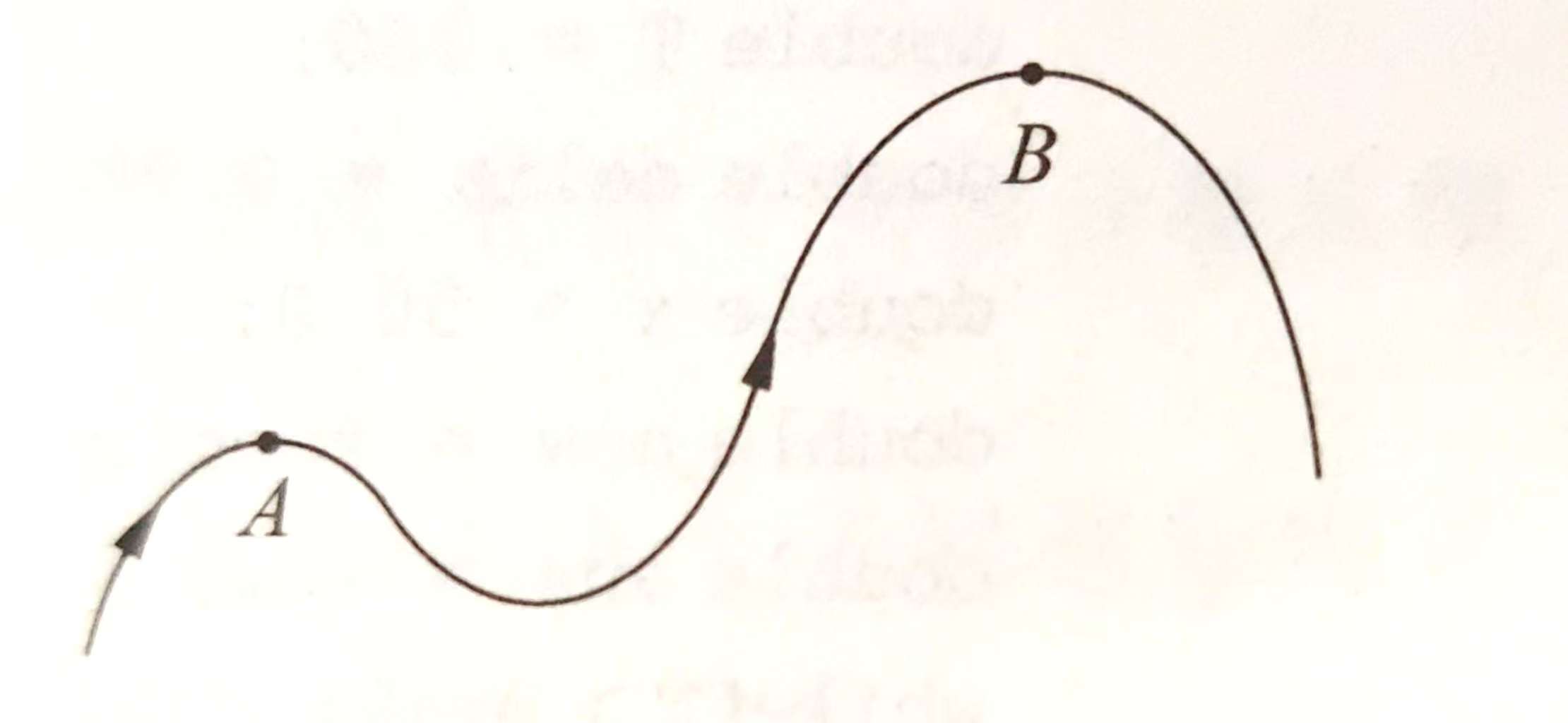
模拟退火算法的主要步骤如下:
(1)设置一个初始的温度T。
(2)温度下降,状态转移。从当前温度按降温系数下降到下一个温度,在新的温度计算当前状态。
(3)如果温度降到设定的温度下界,程序停止。
伪代码如下:
eps = 1e-8; // 终止温度,接近于0,用于控制精度。
T = 100; // 初始温度,应该是高温,以100摄氏度为例。
delta = 0.98; // 降温系数,控制退火的快慢,小于1,以0.98为例。
g(x); // 状态x时的评价函数,例如物理意义上的能量。
now,next; // 当前状态和新状态。
while(T>eps){ // 如果温度未降到eps
g(next),g(now); // 计算当前状态和新状态的评价函数值。
dE = g(next) - g(now); // 计算新旧状态的评价函数差值。
if(dE < 0) { // 如果新状态更优
now = next; // 则接受新状态
} else if(exp(dE/T)>rand()) { //如果新状态更差,在一定概率下接受它,e^(dE/T)
now=next;
}
T*=delta; // 降温,模拟退火过程
}
模拟退火算法典型应用有函数最值问题、TSP旅行商问题、最小园覆盖、最小球覆盖等。下面给出一个求函数最值的例子
例题
Entropy
函数 $ F(x) = 6 x^{2} +8x^{6}+7x^{3}+5^{2}-yx $ ,其中x的取值范围为 $ 0\le x\le 100 $
下面是编程思路
# include <bits/stdc++.h>
using namespace std;
const double eps =1e-8; // 终止温度
double y;
double func(double x){ // 计算函数值
return 6*pow(x,7.0)+8*pow(x,6.0)+7*pow(x,3.0)+5*pow(x,2.0)-y*x;
}
double solve(){
double T = 100; // 初始温度
double delta = 0.98; // 降温系数
double x = 50.0; // x的初始值
double now = func(x); // 计算初始函数值
double ans = now; // 返回值
while (T > eps){ // eps 是终止温度
int f[2] = {1,-1};
double newx = x +f[rand() % 2] * T; // 按概率改变x,随T的降温而减少
if (newx >= 0 && newx<=100){
double next = func(newx);
ans = min(ans, next);
if(now - next > eps){ // 跟新 x
x = newx;
now = next;
}
T *= delta;
}
return ans;
}
}
int main() {
int cas;
scanf("%d", &cas);
while (cas --){
scanf("%lf", &y);
printf("%.4lf\n", solve());
}
}
分析
模拟退火算法用起来非常简单、方便,不过也有缺点。它得到的是一个可行解,而不是精确解。例如上面的例题,计算到4位小数点的精度就停止,实际上是一个可行解,所以算法的效率和要求的精度有关。在一般情况下,模拟退火算法的复杂度会比其他精确算法差。在应用时需要仔细选择初始温度T、降温系数delta、终止温度eps等。




