基本概念
分治法是广为人知的算法思想,很容易理解。人们在遇到一个难以直接解决的大问题时,自然会想到把它划分成一些规模较小的子问题,各个击破,“分而治之(Divide and Conquer)”.
分治算法的具体操作是把原问题分成k个较小规模的子问题,对这k个子问题分别求解。如果子问题不够小,那么把每个子问题再划分为规模更小的子问题。这样一直分解下去,直到问题足够小,很容易求出这些小问题的解为止。
能用分治法的题目需要符合以下特征。
(1) 平衡子问题:子问题的规模大致相同,能把问题划分成大小差不多相等的k个子问题,最好k=2,即分成两规模相等的子问题。子问题规模相等的处理效率比子问题规模不等的处理效率要高。
(2) 独立子问题:子问题直接相互独立。这是区别于动态规划算法的根本特征,在动态规划算法中,子问题是相互联系的,而不是相互独立的。
特别需要说明的是,分治法不仅能够让问题变得更容易理解和解决,而且能大大优化算法的复杂度,在一般情况下能把 $ O(n) $ 的复杂度优化到 $ O(log_{2}n) $ 。这是因为,局部的优化有利于全局;一个子问题的解决,其影响力扩大了k倍,即扩大了到了全局。
举一个简单的例子:在一个有序的数列中查找一个数。简单的办法是从头找到尾,复杂度是 $ O(n) $ 。如果用分治法,即“折半查找”,则最多只需要 $ O(log_{2}n) $ 次就能找到。
分治法是一种“并行”算法。由于子问题是相互独立的,因此可以把子问题分给不同的计算机,分开单独解决。
分治法如何编程?分治法的思想几乎就是递归的过程,用递归程序实现分治法是很自然的。
在用分治法建立模型时,解题步骤分为以下3步。
(1)分解(Divide): 把问题分解成独立的子问题。
(2)解决(Conquer): 递归解决子问题。
(3)合并(Combine): 把子问题的结果合并成原问题的解。
分治法的经典应用有汉诺塔、快速排序、归并排序等。
归并排序
归并排序和快速排序都是非常精美的算法,学习他们,对于理解分治法思想、提高算法思维能力十分有帮助。在学习归并排序和快速排序之前,需要先了解交换排序、选择排序、冒泡排序等暴力的排序方法。
根据分治法的分解、解决、合并三步骤,具体思路如下:
(1) 分解。把原来无序的数列分成两个部分,对每个部分,再继续分解成更小的两部分,一直循环下去。在归并排序中,只是简单地把数列分成两边。在快速排序中,是把序列分成左、右两个部分,左部分的元素都小于右部分的元素。分解操作是快速排序的核心操作。
(2) 解决。分解到最后不能再分解,排序。
(3) 合并。把每次分开的两个部分合并在一起。归并排序的核心操作是合并,其过程类似于交换排序。快速排序并不需要合并操作,因为在分解过程中左、右部分已经是有序的。
归并排序示例
下面的例子给出了归并排序的操作步骤。初始数列经过3趟归并之后得到一个从小到大的有序数列,如下图所示。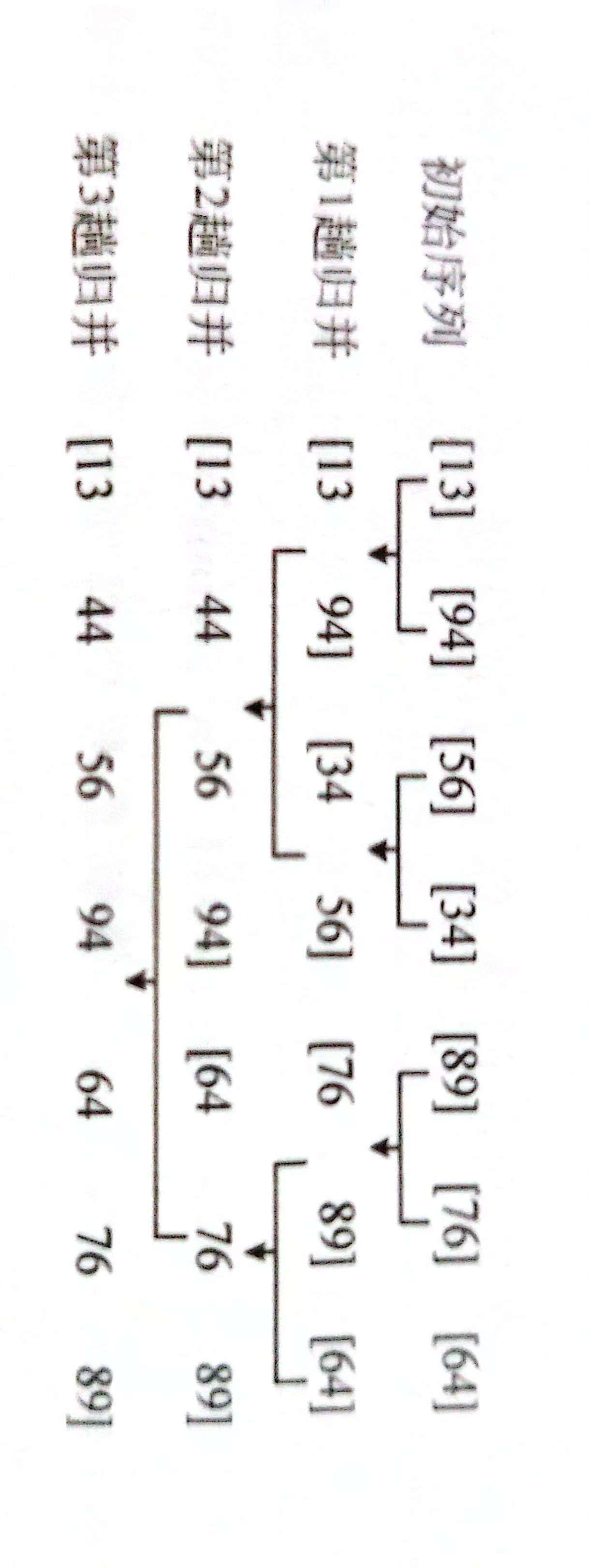
(1) 分解。把初始序列分成长度相同的左、右两个子序列,然后把每个子序列再分成更小的两个子序列,直到子序列只包含1个数。这个过程用递归实现,图中的第1行是初始序列,每个数是一个子序列,可以看成递归到达的最底层。
(2) 求解子问题,对子序列排序。最底层的子序列只包含1个数,其实不用排序。
(3) 合并。归并两个有序的子序列,这是归并排序的主要操作,过程如下图所示。例如在(a)中,i和j分别指向子序列{13,94,99}和{34.56}的第一个数,进行第1次比较,发现 a[i] < a[j], 把 a[i] 放到临时空间 b[ ]中。总共进过4次比较,得到了b[ ]={13,34,56,94,99}。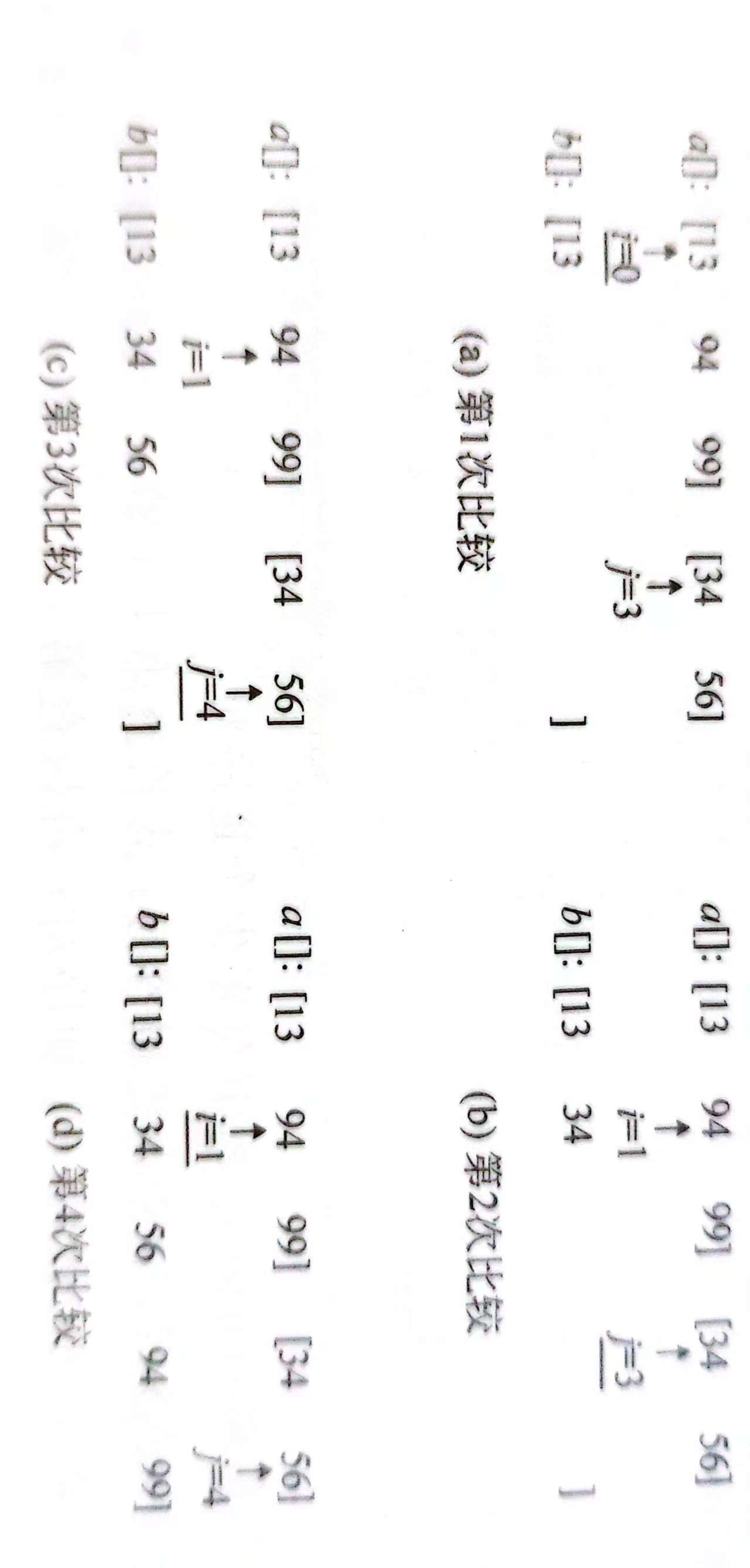
在暴力排序算法中,有一种算法是交换排序,归并排序可以看成是交换排序的升级版。
交换排序的步骤如下:
(1) 第1轮,检查第1个数 $ a_{1} $。把序列中后面所有的数一个个跟它比较,如果发现有一个比 $ a_{1} $ xioa ,就交换。第1轮结束后,最小的数就排在了第1个位置。
(2) 第2抡,检查第2个数。第2轮结束后,第2小的数排在了第2个位置。
(3) 继续上述过程,直到检查完最后一个数。
交换排序的复杂度是 $ O(n^{2}) $
在归并排序中,一次合并的操作和交换排序很相似,只是合并的操作是基于两个有序的子序列,效率更高。
下面分析归并排序的计算复杂度。对n个数进行归并排序:①需要 $ log_{2}n $ 趟归并。 ②在每一趟归并中有很多次合并操作,一个需要 $ O(n) $ 次比较。所以计算复杂度是 $ O(nlog_{2}n) $
空间复杂度:由于需要一个临时的b[ ]存储结果,所以空间复杂度是O(n)。
我们可以从归并排序的例子可以体会到,对于整体上O(n)复杂度的问题,通过分治可以减少为 $ O(log_{2}n) $ 复杂度的问题。
逆序对问题
排序是常用的功能,一般直接使用STL的sort()函数,并不需要自己再写一个排序的程序。不过也会遇到一些特殊的问题,需要在排序的时候做一些处理,就比如逆序对问题。
Inversion
输入一个序列 $ { a_{1} , a_{2} , a_{3} , \dots , a_{n} } $ ,交换任意两个相邻元素,不超过k次。在交换之后,问最少的逆序对有多少个?
序列中的一个逆序对是指存在两个数 $ a_{i} $ 和 $ a_{j} $ ,有 $ a_{i} > a_{j} $ 且 $ 1 \le i < j \le n $ 。也就是说,大的数排在小的数前面。
输入:第1行是n和k,$ 1 \le n \le 10^{5} , 0 \le k \le 10^{9} $ ; 第2行包括n个整数
$ { a_{1} , a_{2} , a_{3} , \dots , a_{1} } , 0 \le a_{i} \le 10^{9} $
输出: 最少的逆序对数量
输入样例:
3 1
2 2 1
输出样例:
1
当k=0时,就是求原始序列中有多少个逆序对。
求k=0时的逆序对,用暴力法很容易:先检查第1个数 $ a_{1} $ ,把后面的所有数跟它比较,如果发现有一个比 $ a_{1} $ 小,就是一个逆序对;再检查第2个数,第3个数……直到最后一个数。其复杂度是 $ O(n^2) $ 。本题中n最大是10^5,所以暴力法会TLE。
考察暴力法的过程,会发现和交换排序很像。那么自然可以想到,能否用交换排序的升级版——归并排序来处理逆序对问题?
观察上图一次合并可以发现,可以利用这个过程记录逆序对。观察到以下现象:
(1)在子序列内部,元素都是有序的,不存在逆序对;逆序对只存在于不同的子序列之间。
(2)在合并两个子序列时,如果前一个子序列的元素比后面的子序列元素小,那么不产生逆序对,如上图(a)所示。如果前一个子序列的元素比后面子序列的元素大,就会产生逆序列,如上图(b)所示。不过在一次合并中,产生的逆序对,不止一个,例如在上图(b)中,把34放到b[ ]中时,它与94、99产生了两个逆序对。在下面的程序中,相关代码是 “cnt+=mid-i+1;” 。
根据以上观察,只要在归并排序过程中记录逆序对就行了。
以上解决了k=0时原始序列中有多少个逆序对的问题,现在考虑,当k不为0时(即把序列中任意两个相邻数交换不超过k次)逆序对最少有多少?注意,不超过k次的意思是可以少于k次,而不是一定要k次。
在所有相邻数中,只有交换那些逆序的才会影响逆序对的数量。设原始序列有cnt个逆序对,讨论以下两种情况:
(1)如果 $ cnt \le k $ , 总逆序数量不够交换k次。所以进行k次交换后,最少的逆序对数量为0.
(2)如果 $ cnt > k $, 让k次交换都发生在逆序的相邻数上,那么剩余的逆序对是cnt—k 。
求逆序对的程序几乎可以完全套用归并排序的模板,差不多就是归并排序的裸题。在下面程序中,Mergesort()和Merge()是归并排序。与纯归并排序的程序相比,它只多了一句 “cnt+=mid-i+1;”
# include <bits/stdc++.h>
using namespace std;
const int MAXN = 100005;
typedef long long ll;
ll a[MAXN], b[MAXN], cnt;
void Merge(ll l, ll mid, ll r){
ll i = l, j = mid + 1, t = l;
while ( i <= mid && j <= r){
if (a[i]>a[j]){
b[t++] = a[j++];
cnt += (mid - i + 1); // 记录逆序对的数量
}
else b[t++] = a[i++];
}
//一个子序列中的数都处理完了,另一个还没有,把剩下的直接复制过来
while (i <= mid) b[t++] = a[i++];
while (j <= r) b[t++] = a[j++];
for(i=0;i<t;i++) a[l+i] = b[l]; // 把排好序的b[]复制回a[]
}
void Mergesort(ll l, ll r){
if ( l < r ){
ll mid = (l + r) / 2; // 平分成两个子序列
Mergesort(l, mid); // 左半边
Mergesort(mid + 1, r); // 右半边
Merge(l, mid, r); // 合并
}
}
int main(){
ll n,k;
while (scanf("% lld % lld",&n,&k)!=EOF){
cnt = 0; // 初始化逆序对计数
for (ll i = 0; i < n; i++) scanf("%lld", &a[i]); // 输入数组
Mergesort(0, n - 1); // 执行归并排序
if (cnt <= k) printf("0\n");
else printf("% I64d\n",cnt - k); // 输出逆序对数量减去k的结果
}
return 0;
}
快速排序
快速排序的思路是:把序列分成左右两个部分,使得左边所有的数都比右边的数小;递归这个过程,直到不能再分为止。
那么如何把序列分成左、右两部分?最简单的办法是设定两个临时空间X、Y和一个基准数t;检查序列中所有的元素,比t小的放在X中,比t大的放在Y中。其实不用这么麻烦,直接在原序列上操作就行了,不需要使用临时空间X、Y。
直接在原序列上进行划分的方法也有很多,下面的例子介绍了一种很容易操作的方法:
用上述方法完成快速排序:
# include <bits/stdc++.h>
const int N = 10010;
int data[N];
# define swap(a,b) {int temp=a; a=b; b=temp;} //交换
int partition(int left, int right){
int i = left;
int temp = data[right]; // 把尾部的数看成基数
for(int j = left; j < right; j++){
if(data[j] <= temp){ // 如果当前数小于等于基数
swap(data[i], data[j]); // 交换
i++; // 增加i的值
}
}
swap(data[i], data[right]); // 把基数放到正确的位置
return i; // 返回基数的位置
}
void quickSort(int left, int right){
if(left < right){ // 如果左边小于右边
int i = partition(left, right); // 划分
quickSort(left, i - 1); // 对左边进行快速排序
quickSort(i + 1, right); // 对右边进行快速排序
}
}
int main(){
int n;
scanf("%d", &n); // 输入数据的个数
for(int i = 0; i < n; i++){
scanf("%d", &data[i]); // 输入数据
}
quickSort(1, n); // 调用快速排序
printf("%d\n", data[(n+1)/2]); // 输出第一个数
return 0;
}
下面分析复杂度。
每一次划分,都把序列分成了左右两部分,在这个过程中,需要比较所有的元素,有O(n)次。如果每次划分是对称的,也就是说左、右两部分的长度差不多,那么一共需要划分 $ O(log_{2} n) $ 次。其总复杂度是 $ O(nlog_{2} n) $ 。
如果划分不是对称的,左部分和右部分的数量差异特别大,那么复杂度会高一些。在极端情况下,例如左部分只有一个数,剩下的全部都在右部分,那么最多可能划分n次,总复杂度是 $ O(n^{2}) $ 。所以,快速排序是不稳定的。
不过,一般情况下,快速排序效率很高,甚至比稳定的归并排序更好。我们可以观察到,快速排序的代码比归并排序的代码简洁,代码中的比较、交换、复制操作很少。快速排序几乎是目前所有排序法中速度最快的方法。STL的sort()函数就是基于快速排序算法的,并针对快速排序的缺点做了很多优化。
快 速排序思想可以用来解决一些特殊问题,例如求第k大数问题。
求第k大的数,简单的方法是用排序算法进行排序,然后定位第k大的数,其复杂度是 $ O(nlog_{2} n) $ 。
如果用快速排序的思想,可以在O(n)的时间内找到第k大的数。在快速排序程序中,每次划分的时候只要递归包含第k个数的那部分就好。




