基本概念
程序运行时需要的资源有两种,即计算时间和存储空间。资源是有限的,一个算法对这两个资源的使用程度可以用来衡量该算法的优劣。
时间复杂度:程序运行需要的时间
空间复杂度:程序运行需要的存储空间
我们希望通过算法解决的问题,在逻辑、数学、算法上有不同的难度:简单的,可以一眼看懂;复杂的,往往需要很多步骤才能找到解决方案。它们对程序性能考核的要求是程序必须在限定的时间和空间内运行结束、
这是因为,问题的“有效”解决不仅在于能否得到正确答案,更重要的是能在合理的时间和空间内给出答案。
时间复杂度
如何衡量程序的时间效率?测量程序在计算机上运行的时间,可以得到一个直观的认识。
下面的程序只有一个 for 语句,它对 k 进行累加,循环次数是 n。该程序用 clock()函数统计 for 循环的运行时间。
# include <bits/stdc++.h>
using namespace std;
int main(){
int i, k, n = 1e8;
clock_t start, end;
start = clock();
for(i = 1; i<n; i++) k++; //循环次数
end = clock();
cout << (double)(end - start) / CLOCKS_PER_SEC << endl;
} 上面的程序在一台普通配置的计算机上运行,例如 CPU 为 i5-8250U、内存为 8GB、64 位的操作系统,结果如下:
当 n=1e8 时,输出的运行时间是 0.164s。
当 n=1e9 时,输出的运行时间是 1.645s。
所以,如果有要求”Time Limit: 2000/1000ms(Java/Others)”,那么内部的循环次数应该满足 n<1e8,即 1 亿次内。
由于程序的运行时间依赖于计算机的性能,不同的计算机结果不同,所以直接把运行时间作为判断标准并不准确。通常,用程序执行的“次数”来衡量更加合理,例如上述程序循环了 n 次,把它的运行效率记为 $ O(n) $ .
下面用一个例子来说明对同样的问题如何选用不同的解法。
排序
Time Limit: 6000/1000ms (JAVA/Others)
Memory Limit: 64/32MB (JAVA/Others)
给出 n 个整数,请按从大到小的顺序输出其中前 m 大的数。
输入:每组测试数据有两行,第 1 行有两个数 n 和 m(0 < n , m < 1000000 ),第 2 行包含 n 个各个不相同,且都处于区间[-500000,500000]的整数。
输出:对每组测试数据按从大到小的顺序输出前 m 大的数。
输入样例:
5 3
3 -35 92 213 -644
输出样例:
213 92 3
该题的思路是先对 100 万个数排序,然后输出前 m 大的数。题目给出了代码运行时间,非 JAVA 语言的时间是 1s,内存是 32MB。
下面分别用冒泡排序、快速排序、哈希 3 种算法编程。
冒泡排序
# include <bits/stdc++.h>
using namespace std;
int a[1000001];
# define swap(a,b) {int temp = a; a = b; b = temp;}
int n,m;
void bubble_sort(){ // 冒泡排序
for(int i =1; i<=n-1;i++){
for(int j = 0; j<n-i;j++){
if(a[j]>a[j+1]){
swap(a[j],a[j+1]);
}
}
}
}
int main(){
while (~scanf("%d%d", &n, &m)) {
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
bubble_sort();
for (int i = 0; i >=n-m+1; i--) { // 打印前m大的数,反序打印
if(i==n-m+1){
printf("%d\n", a[i]);
} else {
printf("%d ", a[i]);
}
}
}
return 0;
}
在 bubble_sort()运行后,得到从小到大的排序结果,然后从后往前打印前 m 大的数。冒泡排序算法的步骤如下:
(1)第一轮,从第 1 个数到第 n 个数,逐个对比每两个相邻的数 a、b,如果 a>b,则交换。这一轮的结果是把最大的数“冒泡”到了第 n 个位置,在后面不用再管它。
(2)第二轮,从第 1 个数到第 n-1 个数,对比每两个相邻的数。这一轮,把第二大的数“冒泡”到了第 n-1 个位置。
(3)继续以上程序直到结束。
下面分析程序的时间和空间效率。
(1)时间复杂度,也就是程序执行了多少步骤,花了多少时间。
在 bubble_sort()中有两层循环,循环次数是 $ n-1+n-2+\cdots +1\approx n^{2} /2 $ ;在 swap(a,b)中做了 3 次操作;总的计算次数是 $ 3n^{2} /2 $ , 复杂度记为 $ O(n^{2}) $ 。当 n=100 万时,计算超过 1 万亿次。如果提交到 OJ,由于 OJ 每秒只能运行 1 亿次,必然返回 TLE 超时。可以推出,只有 n<1 万时才勉强能用冒泡算法。
(2)空间复杂度,也就是程序占用的内存空间。程序使用 int a[1000001]存储数据,bubble_sort()也没有使用额外的空间。int 是 32 为整数,占用 4 个字节,所以 int[1000001]共使用了 4MB 空间。这是冒泡算法的优点,它不占用额外的空间。
快速排序
快速排序是一种基于分治法的优秀排序算法。这里先直接用 STL 的 sort()函数,它是改良版的快速排序,称为”内省式排序”。
在上面的程序中,把”bubblesort();”改为”sort(a+1,a+n+1);”就完成了 a[1]到 a[n]的排序,结果仍然保存在 a[]中。
算法的时间复杂度 O(nlog{2}n),当 n=100 万时,大约需要 2000 万次运算。
在 hdu 上提交,返回的运行时间是 600ms,正好通过 OJ 测试。
哈希算法
哈希算法是一种以空间换取时间的算法。本题的哈希思路是:在输入数字 t 的时候,在 a[500000+t]这个位置记录 a[500000+t]=1.在输出的时候逐个检查 a[i],如果 a[i]等于 1,表示这个数存在吗,打印出前 m 个数。程序如下:
# include <bits/stdc++.h>
using namespace std;
const int MAXN = 1000001;
int a[MAXN];
int main(){
int n,m;
while(~scanf("%d%d",&n,&m)){
memset(a,0,sizeof(a));
for(int i = 0; i < n; i++){
int t;
scanf("%d",&t);
a[500000+t]=1;
}
for(int i = MAXN -1;m>0;i--){
if(a[i]){
if(m>1) printf("%d",i-500000);
else printf("%d\n",i-500000);
m--;
}
}
return 0;
}
}程序并没有做显式的排序,只是每次把输入的数按哈希插入到对应为止,只有 1 次操作;n 个数输入完毕,就相当于排好序了。总的时间复杂度是 O(n)。在 hdu 上提交,返回的运行时间是 500ms。
空间复杂度
类似于时间复杂度的讨论,一个算法的空间复杂度 S(n)定义为该算法所耗费的存储空间,它也是问题规模 n 的函数。渐近空间复杂度也常常简称为空间复杂度。空间复杂度(SpaceComplexity)是对一个算法在运行过程中临时占用存储空间大小的量度。一个算法在计算机存储器上所占用的存储空间,包括存储算法本身所占用的存储空间,算法的输入输出数据所占用的存储空间和算法在运行过程中临时占用的存储空间这三个方面。算法的输入输出数据所占用的存储空间是由要解决的问题决定的,是通过参数表由调用函数传递而来的,它不随本算法的不同而改变。存储算法本身所占用的存储空间与算法书写的长短成正比,要压缩这方面的存储空间,就必须编写出较短的算法。算法在运行过程中临时占用的存储空间随算法的不同而异,有的算法只需要占用少量的临时工作单元,而且不随问题规模的大小而改变,我们称这种算法是“就地"进行的,是节省存储的算法,有的算法需要占用的临时工作单元数与解决问题的规模 n 有关,它随着 n 的增大而增大,当 n 较大时,将占用较多的存储单元,例如快速排序和归并排序算法就属于这种情况。
算法常见的时间复杂度
有一点需要额外注意,时间复杂度只是一个估计,并不需要精确计算。例如,在一个有n个数的无需数列中查找某个数x,可能第一个数就是x,也可能最后一个数才是x,平均查找时间是n/2次,但是把查找的时间复杂度记为O(n),而不是O(n/2)。再如,冒泡排序算法的计算次数约等于 $ n^{2} /2 $ , 但是仍记为 O(n^{2})。在算法分析中,规模n前面的常数系数被认为是不重要的。下面罗列了一些常见的时间复杂度:
O(1)
计算时间是一个常数,和问题的规模n无关。例如,用公式计算时,一次计算的复杂度就是O(1);哈希算法,用hash函数在常数时间内计算出存储位置;在矩阵A[M][N]中查找第i行第j列的元素,只需要访问A[i][j]就够了。
$ O(log_{2}n) $
计算时间是对数,通常是以2为底的对数,每一步计后,问题的规模减小一倍。例如,在一个长度为n的有序数列中查找某个数,用折半查找的方法只需要 $ log_{2}n $ 次就能找到。再如分治法,一般情况下,在每个步骤把规模减小一倍,所以一共有 $ O(log_{2}n) $ 个步骤。
$ O(log_{2}n) $ 和 O(1) 没有太大区别.
O(n)
计算时间随规模n线性增长。在很多情况下,这是算法可能达到的最优复杂度,因为对输入的n个数,程序一般需要处理所有的数,即计算n次。例如查找一个无序数列中的某个数,可能需要检查所有的数。再如图问题,有V个点和E个边,大多数图的问题都需要搜索到所有的点和边,复杂度的上限就是O(V+E).
$ O(nlog_{2}n) $
这常常是算法能达到的最优复杂度。例如分治法,一共 $ O(log_{2}n) $ 个步骤,每个步骤对每个数操作一次,所以总复杂度是 $ O(nlog_{2}n) $ .用分治法思想实现的快速排序算法和归并排序算法的复杂度是 $ O(nlog_{2}n) $ 。
$ O(n^{2}) $
一个两重循环的算法,复杂度是 $ O(n^{2}) $ 。例如冒泡排序是典型的两重循环。
$ O(2^{n}) $
一般对应集合问题,例如一个集合中有n个数,要求输出它的所有子集,子集有 $ 2^{n} $ 个。
O(n!)
在排列问题中,如果要求输出所有的全排列,那么复杂度就是O(n!)。
可接受的复杂度
把上面的复杂度分成两类:
①多项式复杂度,包括O(1)、O(n)、 $ O(nlog_{2}n)、 O(n^{k}) $ 等,其中k上一个常数;
②指数复杂度,包括 $ O(2^{n}) 、 O(n!) $ 等。
如果一个算法是多项式复杂度,称他为”高效“算法;如果一个算法是指数复杂度 ,则称它为“低效”算法。可以这样通俗地解释“高效”和“低效”算法的区别:多项式复杂度的算法随着规模n的增加可以通过堆叠硬件来实现,“砸钱”是行得通的;而指数复杂度的算法增加硬件也无济于事,其增长速度超出了人们的想象力。
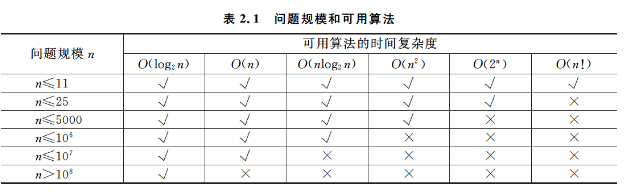
问题的规模和可用算法