基本概念
通俗地讲,机器学习(Machine Learning, ML) 就是让计算机从数据中进行自动学校,得到某种知识(或规律)。作为一门学科,机器学习通常指一类问题以及解决这类问题的方法,即如何从观测数据(样本)中寻找规律,并利用学习到的规律(模型)对未知或无法观测的数据进行预测。那么如何让机器来学习这些知识呢?
首先我们可以将一个标记好的特征以及标签的事物看作一个 样本(Sample) ,也经常称为 示例(Instance) 。而机器就是要根据许多样本的特征,和其对应的结果,自己去学习总结出其中的关系,总结出事物的特征对结果的影响程度。一组样本构成的集合称为数据集(Data Set).一般将数据集分为两部分:训练集和测试集。训练集(Training Set) 中的样本是用来训练模型的,也叫训练样本(Training Sample),而 测试集(Test Set) 中的样本是用来检验模型好坏的,也叫测试样本(Test Sample)。也就是当我们把大量的数据样本的特征(自变量)和其对应的结果(因变量)分为成两部分,第一部分为训练集,用来让机器学习其中的规律。另一部分是测试集,机器只能看到该集合的自变量,然后根据通过训练集学习到规律,去给出测试集的结果(预测的因变量)。最后将这些预测的结果和实际的结果相比对,以判断学习的成果。
我们通常用一个D维向量 $ \overrightarrow{x} =\left [ x_{1},x_{1},\cdots ,x_{D} \right ]^{T} $ 表示事物的所有特征构成的向量,成为特征向量(Feature Vector),其中每一维表示一个特征。而想通过事物获得的结果通常用标量y来表示。
假设训练集 $ \mathcal{D} $ 由N个样本组成,其中每个样本都是 独立同分布的 (Identically and Independently Distributed, IID),即独立地从相同的数据分布中抽取的,记为
$$ \mathcal{D} =\left { (\overrightarrow{x}^{(1)},y^{(1)}),(\overrightarrow{x}^{(2)},y^{(2)}),\cdots ,(\overrightarrow{x}^{(N)},y^{(N)}) \right } $$
给定训练集 $ \mathcal{D} $,我们希望让计算机从一个函数集合 $\mathcal{F} =\left { f_{1}(\overrightarrow{x}),f_{2}(\overrightarrow{x}),f_{3}(\overrightarrow{x}),\cdots \right } $ 中自动寻找一个“最优”的函数
$ f^{} (\overrightarrow{x} ) $ 来近似每个样本的特征向量 $ \overrightarrow{x} $ 和标签y之间的真实映射关系。对于一个样本 $ \overrightarrow{x}$ ,我们可以通过函数 $f^{} (\overrightarrow{x} )$ 来预测其标签的值
$$
\hat{y} =f^{} (\overrightarrow{x} )
$$
或标签的条件概率
$$
\hat{p} (y|\overrightarrow{x})=f_{y}^{}(\overrightarrow{x} )
$$
如何寻找这个“最优”的函数 $f^{} (\overrightarrow{x} )$ 是机器学习的关键,一般需要通过学习算法(Learning Algorithm) $ \mathcal{A} $来完成。这个寻找过程通常称为学习(Leaning)或训练(Training)的过程。这样,后面就可以直接通过 $ f^{} (\overrightarrow{x} ) $ 来让机器给出我们合理的答案。为了评价的公正性,我们还是独立同分布地抽取一组数据作为测试集 $ \mathcal{D}’ $,并在测试集中所有数据上进行测试,计算预测结果的准确率
$$
Acc(f^{}(\overrightarrow{x}))=\frac{1}{\mathcal{D}’}\sum_{(\overrightarrow{x} ,y)\in \mathcal{D}’}^{} I(f^{}(\overrightarrow{x})=y)
$$
其中I(·)为指示函数,$\left | \mathcal{D}’ \right | $ 为测试集大小。
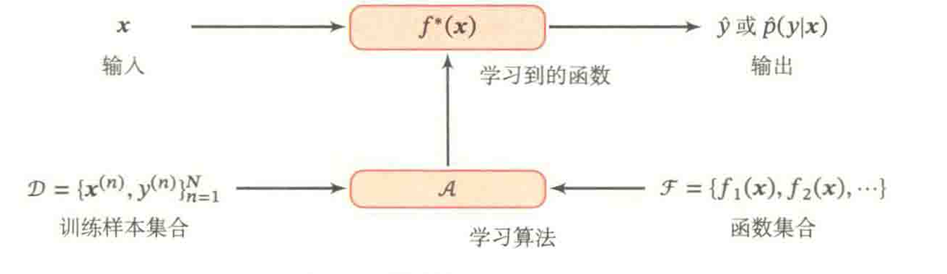
下图给出了机器学习的基本流程。对一个预测任务,输入特征向量为 $ \overrightarrow{x} $,输出标签为y,我们选择一个函数集合 $ \mathcal{F} $ ,通过学习算法 $ \mathcal{A} $,和一组训练样本 $ \mathcal{D} $,从 $ \mathcal{F} $ 中学习到函数 $ f^{}(\overrightarrow{x}) $ . 这样就可以对新的输入$ \overrightarrow{x} $,就可以用函数$ f^{}(\overrightarrow{x}) $进行预测。